Hyperparameter Optimization Example¶
This Jupyter Notebook is made for illustrating - through a mixture of slides and code in an interactive fashion - the different methods for optimising Hyperparameters for Machine Learning models. First it shows the most naive, manual approach, then grid search, and finally bayesian optimization.
Authors and Date:¶
- Christian Michelsen & Troels Petersen (Niels Bohr Institute)
- 2022-05-01 (latest update)
- Naive, manual approach
- Grid search
- Random search
- Bayesian optimization
- "Full" scan over parameter space
- New methods
- New software
- Focus on the understanding of HPO, not the actual code nor the data!
Nomenclature (i.e. naming scheme)¶
- Machine Learning Model: $\mathcal{A}$
- $N$ hyperparameters
- Domain: $\Lambda_n$
- Hyperparameter configuration space: $\mathbf{\Lambda}=\Lambda_1 \times \Lambda_2 \times \dots \times \Lambda_N $
- Vector of hyperparameters: $\mathbf{\lambda} \in \mathbf{\Lambda}$
- Specific ML model: $\mathcal{A}_\mathbf{\lambda}$
Domain of hyperparameters:¶
- real
- integer
- binary
- categorical
Goal:¶
Given a dataset $\mathcal{D}$, find the vector of HyperParameters $\mathbf{\lambda}^{*}$, which performes "best", i.e. minimises the expected loss function $\mathcal{L}$ for the model $\mathcal{A}_\mathbf{\lambda}$ on the test set of the data $D_\mathrm{test}$:
$$ \mathbf{\lambda}^{*} = \mathop{\mathrm{argmin}}_{\mathbf{\lambda} \in \mathbf{\Lambda}} \mathbb{E}_{D_\mathrm{test} \thicksim \mathcal{D}} \, \left[ \mathbf{V}\left(\mathcal{L}, \mathcal{A}_\mathbf{\lambda}, D_\mathrm{test}\right) \right] $$In practice we have to approximate the expectation above.
First, we import the modules we want to use:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn import tree
from sklearn.datasets import load_iris, load_wine
from sklearn.metrics import accuracy_score
from IPython.display import SVG
from graphviz import Source
from IPython.display import display
from ipywidgets import interactive
from sklearn.model_selection import train_test_split, GridSearchCV, RandomizedSearchCV
from scipy.stats import randint, poisson
import warnings
# warnings.filterwarnings('ignore')
We read in the data:
df = pd.read_csv('./data/Pulsar_data.csv')
df.head(10)
We then divide the dataset in input features (X) and target (y):
X = df.drop(columns='Class')
y = df['Class']
feature_names = df.columns.tolist()[:-1]
print(X.shape)
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.20,
random_state=42)
X_train.head(10)
And check out the y values (which turns out to be balanced):
y_train.head(10)
y_train.value_counts()
Part A: Naïve Approach¶
- Manual configuration
- "Babysitting is also known as Trial & Error or Grad Student Descent in the academic field"
def fit_and_grapth_estimator(estimator):
estimator.fit(X_train, y_train)
accuracy = accuracy_score(y_train, estimator.predict(X_train))
print(f'Training Accuracy: {accuracy:.4f}')
class_names = [str(i) for i in range(y_train.nunique())]
graph = Source(tree.export_graphviz(estimator,
out_file=None,
feature_names=feature_names,
class_names=class_names,
filled = True))
display(SVG(graph.pipe(format='svg')))
return estimator
def plot_tree(max_depth=1, min_samples_leaf=1):
estimator = DecisionTreeClassifier(random_state=42,
max_depth=max_depth,
min_samples_leaf=min_samples_leaf)
return fit_and_grapth_estimator(estimator)
display(interactive(plot_tree,
max_depth=(1, 10, 1),
min_samples_leaf=(1, 100, 1)))
(Test this interactively in notebook)
And test this configuration out on the test data:
clf_manual = DecisionTreeClassifier(random_state=42,
max_depth=10,
min_samples_leaf=5)
clf_manual.fit(X_train, y_train)
accuracy_manual = accuracy_score(y_test, clf_manual.predict(X_test))
print(f'Accuracy Manual: {accuracy_manual:.4f}')
Part B: Grid Search¶
Grid Search:
- full factorial design
- Cartesian product
- Curse of dimensionality (grows exponentially)
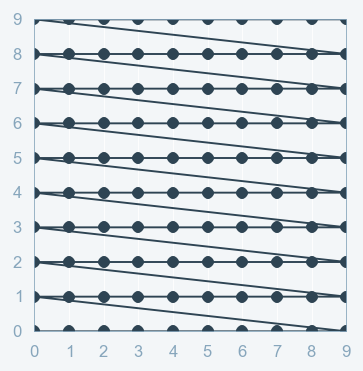
Grid Search with Scikit Learn:
parameters_GridSearch = {'max_depth':[1, 10, 100],
'min_samples_leaf':[1, 10, 100],
}
clf_DecisionTree = DecisionTreeClassifier(random_state=42)
GridSearch = GridSearchCV(clf_DecisionTree,
parameters_GridSearch,
cv=5,
return_train_score=True,
refit=True,
)
GridSearch.fit(X_train, y_train);
GridSearch_results = pd.DataFrame(GridSearch.cv_results_)
print("Grid Search: \tBest parameters: ", GridSearch.best_params_, f", Best scores: {GridSearch.best_score_:.4f}\n")
GridSearch_results
clf_GridSearch = GridSearch.best_estimator_
accuracy_GridSearch = accuracy_score(y_test, clf_GridSearch.predict(X_test))
print(f'Accuracy Manual: {accuracy_manual:.4f}')
print(f'Accuracy Grid Search: {accuracy_GridSearch:.4f}')
Part C: Random Search¶
- $B$ function evaluations, $N$ hyperparameters, $y$ number of different values:
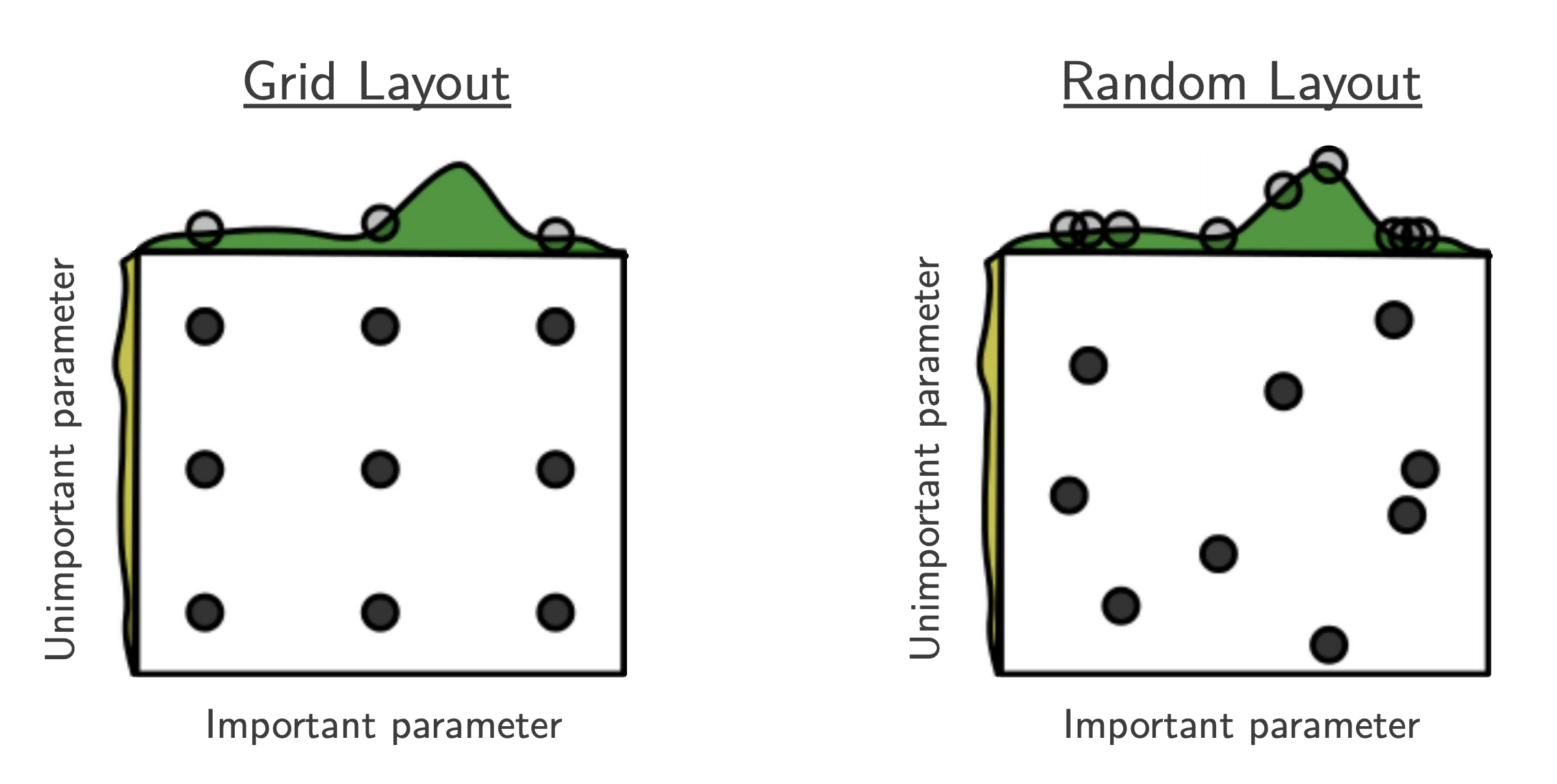
- "This failure of grid search is the rule rather than the exception in high dimensional hyper-parameter optimization" [Bergstra, 2012]
- useful baseline because (almost) no assumptions about the ML algorithm being optimized.
Random Search with Scikit Learn using Scipy Stats as PDFs for the parameters:
# specify parameters and distributions to sample from
parameters_RandomSearch = {'max_depth': poisson(25),
'min_samples_leaf': randint(1, 100)}
# run randomized search
n_iter_search = 9
RandomSearch = RandomizedSearchCV(clf_DecisionTree,
param_distributions=parameters_RandomSearch,
n_iter=n_iter_search,
cv=5,
return_train_score=True,
random_state=42,
)
# fit the random search instance
RandomSearch.fit(X_train, y_train);
RandomSearch_results = pd.DataFrame(RandomSearch.cv_results_)
print("Random Search: \tBest parameters: ", RandomSearch.best_params_, f", Best scores: {RandomSearch.best_score_:.3f}")
RandomSearch_results.head(10)
clf_RandomSearch = RandomSearch.best_estimator_
accuracy_RandomSearch = accuracy_score(y_test, clf_RandomSearch.predict(X_test))
print(f'Accuracy Manual: {accuracy_manual:.4f}')
print(f'Accuracy Grid search: {accuracy_GridSearch:.4f}')
print(f'Accuracy Random Search: {accuracy_RandomSearch:.4f}')
Part D: Bayesian Optimization¶
- Expensive black box functions $\Rightarrow$ need of smart guesses
- Probabilistic Surrogate Model (to be fitted)
- Often Gaussian Processes
- Acquisition function
- Exploitation / Exploration
- Cheap to Computer
[Brochu, Cora, de Freitas, 2010]
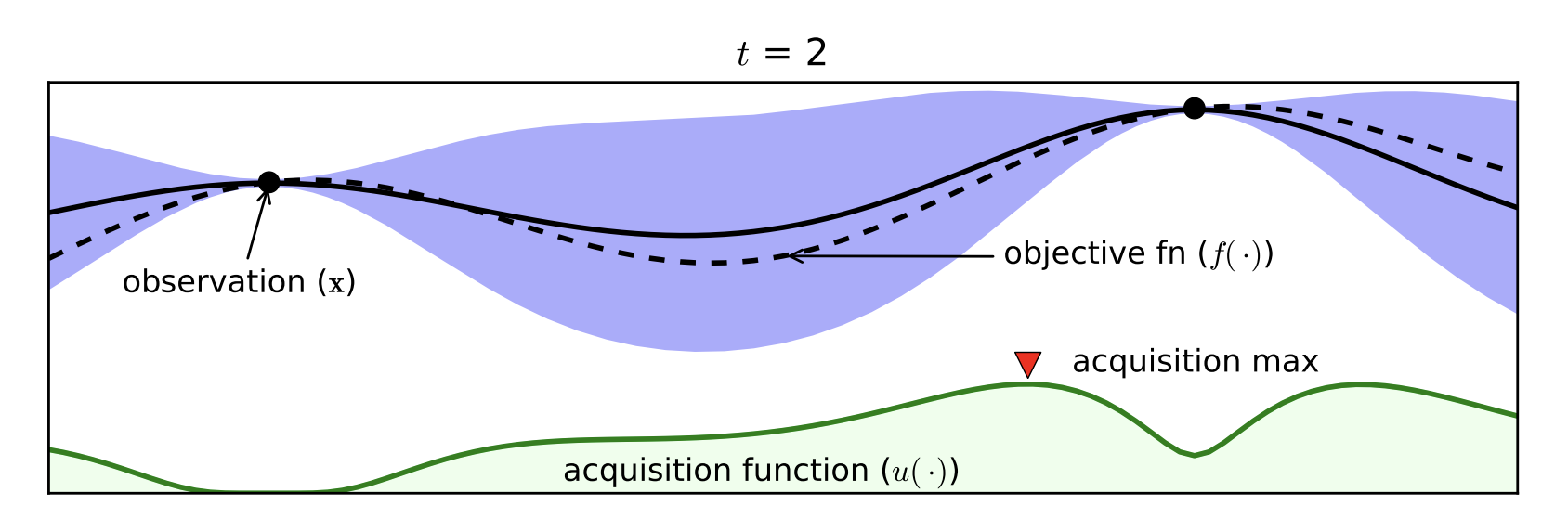
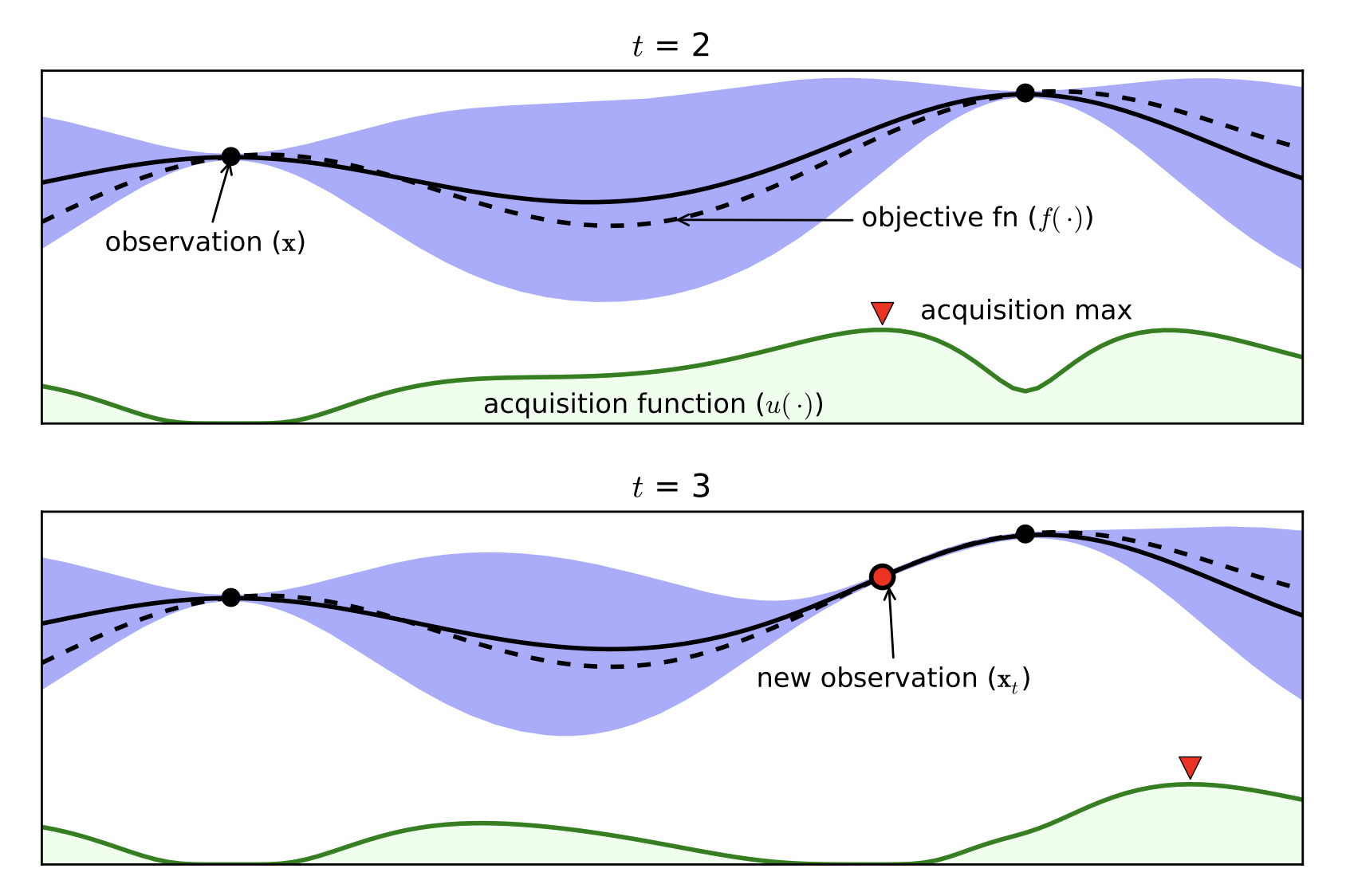
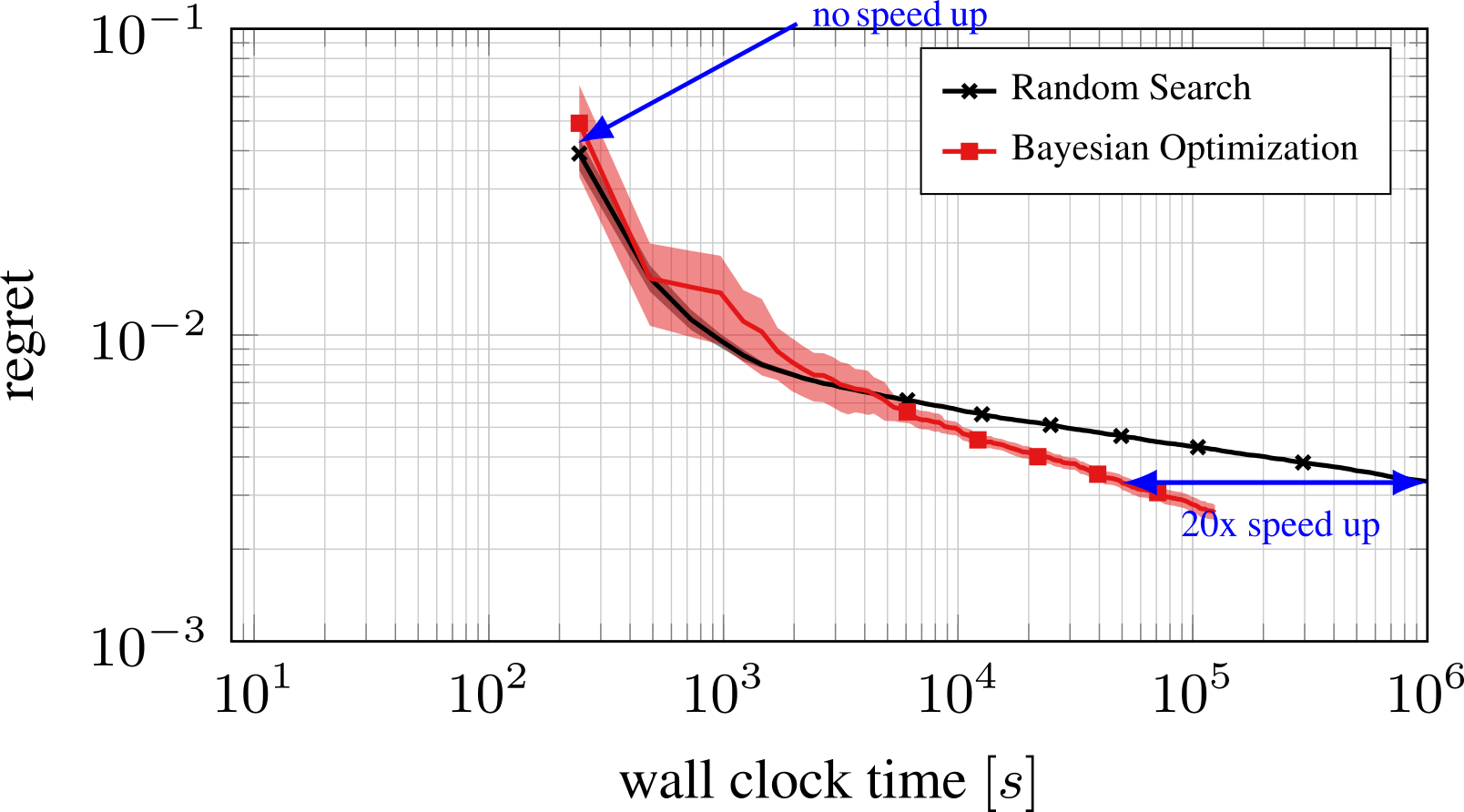
Bayesian Optimization with the Python package BayesianOptimization:
from bayes_opt import BayesianOptimization
from sklearn.model_selection import cross_val_score
def DecisionTree_CrossValidation(max_depth, min_samples_leaf, data, targets):
"""Decision Tree cross validation.
Fits a Decision Tree with the given paramaters to the target
given data, calculated a CV accuracy score and returns the mean.
The goal is to find combinations of max_depth, min_samples_leaf
that maximize the accuracy
"""
estimator = DecisionTreeClassifier(random_state=42,
max_depth=max_depth,
min_samples_leaf=min_samples_leaf)
cval = cross_val_score(estimator, data, targets, scoring='accuracy', cv=5)
return cval.mean()
def optimize_DecisionTree(data, targets, pars, n_iter=5):
"""Apply Bayesian Optimization to Decision Tree parameters."""
def crossval_wrapper(max_depth, min_samples_leaf):
"""Wrapper of Decision Tree cross validation.
Notice how we ensure max_depth, min_samples_leaf
are casted to integer before we pass them along.
"""
return DecisionTree_CrossValidation(max_depth=int(max_depth),
min_samples_leaf=int(min_samples_leaf),
data=data,
targets=targets)
optimizer = BayesianOptimization(f=crossval_wrapper,
pbounds=pars,
random_state=42,
verbose=2)
optimizer.maximize(init_points=4, n_iter=n_iter)
return optimizer
parameters_BayesianOptimization = {"max_depth": (1, 100),
"min_samples_leaf": (1, 100),
}
BayesianOptimization = optimize_DecisionTree(X_train,
y_train,
parameters_BayesianOptimization,
n_iter=5)
print(BayesianOptimization.max)
params = BayesianOptimization.max['params']
clf_BO = DecisionTreeClassifier(random_state=42, **params)
clf_BO = clf_BO.fit(X_train, y_train)
accuracy_BayesianOptimization = accuracy_score(y_test, clf_BO.predict(X_test))
print(f'Accuracy Manual: {accuracy_manual:.4f}')
print(f'Accuracy Grid Search: {accuracy_GridSearch:.4f}')
print(f'Accuracy Random Search: {accuracy_RandomSearch:.4f}')
print(f'Accuracy Bayesian Optimization: {accuracy_BayesianOptimization:.4f}')
Part D: Full Scan over Parameter Space¶
Only possible in low-dimensional space, slow
max_depth_array = np.arange(1, 30)
min_samples_leaf_array = np.arange(2, 31)
Z = np.zeros((len(max_depth_array), len(min_samples_leaf_array)))
for i, max_depth in enumerate(max_depth_array):
for j, min_samples_leaf in enumerate(min_samples_leaf_array):
clf = DecisionTreeClassifier(random_state=42,
max_depth=max_depth,
min_samples_leaf=
min_samples_leaf)
clf.fit(X_train, y_train)
acc = accuracy_score(y_test, clf.predict(X_test))
Z[i, j] = acc
# Notice: have to transpose Z to match up with imshow
Z = Z.T
Plot the results:
fig, ax = plt.subplots(figsize=(12, 6))
# notice that we are setting the extent and origin keywords
CS = ax.imshow(Z, extent=[1, 30, 2, 31], cmap='viridis', origin='lower')
ax.set(xlabel='max_depth', ylabel='min_samples_leaf')
fig.colorbar(CS);

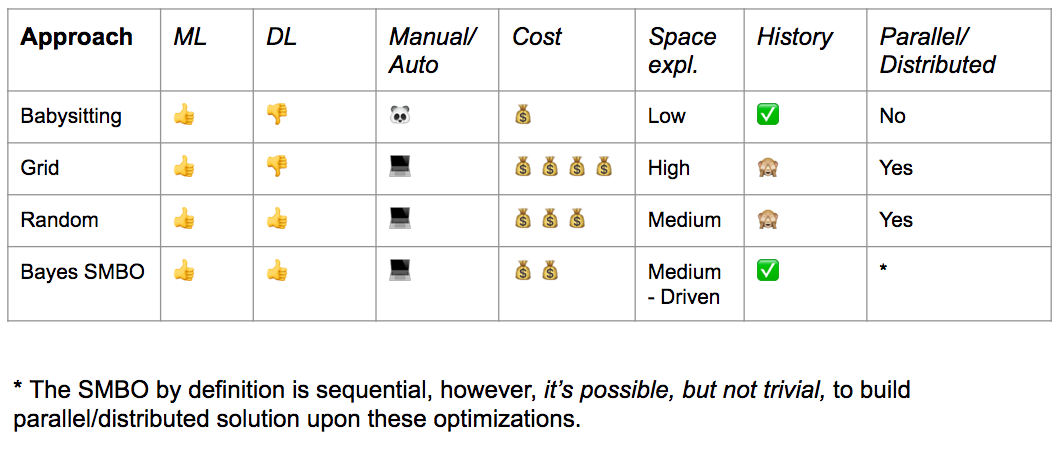
Sum up:¶
Part E: New Methods¶
Bayesian Optimization meets HyperBand (BOHB)
HyperBand:

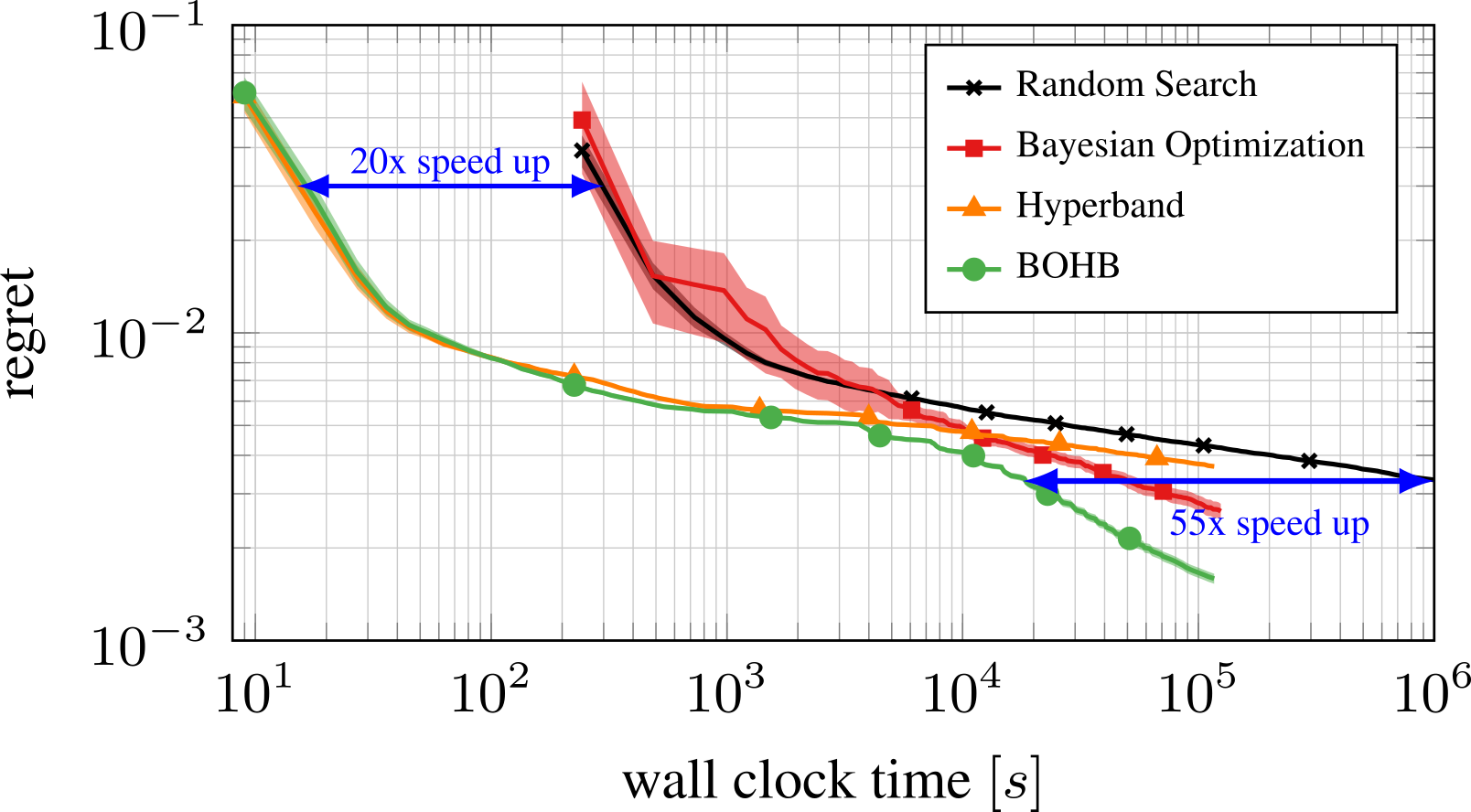
import optuna
from optuna.samplers import TPESampler
from optuna.integration import LightGBMPruningCallback
from optuna.pruners import MedianPruner
import lightgbm as lgb
lgb_data_train = lgb.Dataset(X_train, label=y_train);
def objective(trial):
boosting_types = ["gbdt", "rf", "dart"]
boosting_type = trial.suggest_categorical("boosting_type", boosting_types)
params = {
"objective": "binary",
"metric": 'auc',
"boosting": boosting_type,
"max_depth": 5,
"max_depth": trial.suggest_int("max_depth", 2, 63),
"min_child_weight": trial.suggest_loguniform("min_child_weight", 1e-5, 10),
"scale_pos_weight": trial.suggest_uniform("scale_pos_weight", 10.0, 30.0),
"bagging_freq": 1, "bagging_fraction": 0.6,
"verbosity": -1
}
N_iterations_max = 10_000
early_stopping_rounds = 50
if boosting_type == "dart":
N_iterations_max = 100
early_stopping_rounds = None
cv_res = lgb.cv(
params,
lgb_data_train,
num_boost_round=N_iterations_max,
early_stopping_rounds=early_stopping_rounds,
verbose_eval=False,
seed=42,
callbacks=[LightGBMPruningCallback(trial, "auc")],
)
num_boost_round = len(cv_res["auc-mean"])
trial.set_user_attr("num_boost_round", num_boost_round)
return cv_res["auc-mean"][-1]
study = optuna.create_study(
direction="maximize",
sampler=TPESampler(seed=42),
pruner=MedianPruner(n_warmup_steps=50),
)
study.optimize(objective, n_trials=100, show_progress_bar=True);
# To see all info at the best trial use:
study.best_trial
# To print metric values for all trials:
study.best_trial.intermediate_values
# To see distributions from which optuna samples parameters:
study.best_trial.distributions
# To simply get the optimized parameters:
study.best_trial.params
Happy HyperParameter Optimisation!¶
...and remember, that this is useful but not essential in this course.